I wanted to have fun on the internet again. Around a decade ago (wow, time flies!), I remember lots of little landing pages built just for fun. There were no monetization strategies or traffic expectations. These were websites built simply to showcase fun content, play with fun technologies, or a combination of the two.
Over the holidays I threw together a little site in that category of fun personal websites, and I’ve been iterating on it over the last couple weeks in my spare time. I don’t really care if anyone looks at it, as I’m building it for myself, but I wanted to write up what has gone into it so far.
Origins
I thought it would be fun to have a personal landing page, something that showed what I was up to all over the internet, not just my blog posts, but also what I was listening to or reading. So I started coding up a little site, adding content section by section. I had always intended for it to be able to update on it’s own, my own personal social network aggregator, so I started by checking out the data from the public APIs (or RSS feeds) of the various services I wanted to display. That way I wouldn’t rely on some piece of data that wasn’t going to be accessible when I started to automate things.
I hand-coded the site in plain HTML and CSS, focusing on the content and styling. The first iteration looked something like this:
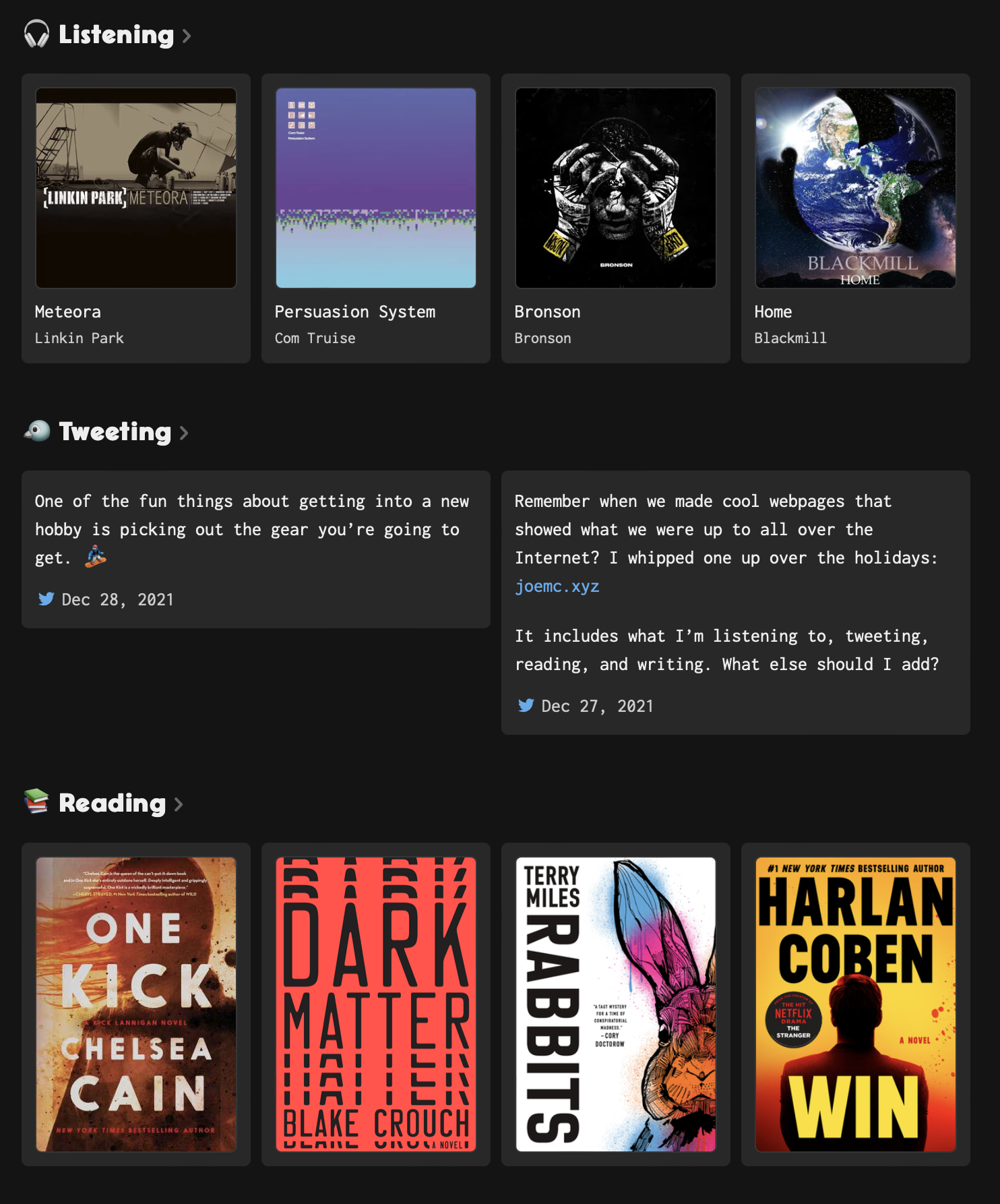
I was liking how things were coming together, but after I published it, the hand-coded beginnings of the site became frustrating to maintain (as expected). If I listened to some music that was scrobbled to last.fm or tweeted, I would feel a need to go in and edit my website with the new album or tweet since it would no longer be accurate on my own landing page. It was time to make it more dynamic.
Data Powered
The first step towards making my landing page self-sustaining was to templatize it. Instead of writing raw HTML, I decided to use Hugo1 to generate the pages based on JSON representations of the objects. For example, I can represent a tweet using this JSON:
1{
2 "link": "https:\/\/twitter.com\/mclaughj\/status\/1475905340877148162",
3 "id": "1475905340877148162",
4 "date": "Dec 28, 2021",
5 "text": "One of the fun things about getting into a new hobby is picking out the gear you’re going to get. 🏂"
6}
And I can render it to HTML using this snippet, using the various attributes of the tweet in the template:
1<div class="tweet">
2 <div class="tweet-content">
3 <span class="text">{{ .text | markdownify }}</span>
4 {{ if ne .image nil }}<img src="{{ .image }}">{{ end }}
5 </div>
6 <div class="meta">
7 <a href="{{ .link }}">{{ .date }}</a>
8 </div>
9</div>
After switching over to a templatized site with all of the various sections powered by JSON files, I was ready for the next step: dynamically fetching the data.
Enter Swift
The language I’ve written the most code in over the last five or so years has been Swift, so it’s the language I decided to lean on for fetching the most recent data to power my little site.
A few services I wanted to pull data from had public APIs with fairly straightforward integration steps. Others didn’t have public APIs, but they did offer RSS feeds with my most recent data, so I parsed the XML from those feeds and translated them into the format I was already using on my website from the previous step.
In all cases, once I had the data from the APIs or feeds, I needed to translate and assemble the data in a format that would work for my site. I wrote some simple Codable models that accepted my decoded Swift object in initializers to mold the data into the right formats. For example, here’s my Book model:
1struct Book: Codable {
2 let title: String
3 let author: String
4 let link: String
5 let image: String
6
7 init(with grBook: GRBook) {
8 title = grBook.title
9 author = grBook.author
10 link = "https://www.goodreads.com/book/show/\(grBook.id)"
11 image = grBook.image
12 }
13}
One that was a bit more fun was tweets, since I also needed to generate valid markdown for the template shown earlier. At a minimum, I needed to wrap URLs with markdown link syntax, but I also took this opportunity to replace the shortened t.co links with whatever the link text was that I used when I wrote the original tweet. I may do some additional modification here in order to display images inline (by default from the API they’re pic.twitter.com links), but for now I’m happy with this:
1struct Tweet: Codable {
2 let id: String
3 let text: String
4 let link: String
5 let date: String
6
7 init(with tTweet: TTweet) {
8 var modifiedText = tTweet.text
9 if let entities = tTweet.entities,
10 let urls = entities.urls {
11 urls.forEach { url in
12 modifiedText = modifiedText.replacingOccurrences(of: url.tCoUrl, with: "[\(url.displayUrl)](\(url.expandedUrl))")
13 }
14 }
15 text = modifiedText
16 link = "https://twitter.com/mclaughj/status/\(tTweet.id)"
17 date = tTweet.date
18 id = tTweet.id
19 }
20}
One other cool thing I implemented was diffing the new data against the data I already have on disk for my site. This avoids some followup API requests, and allows me to extend the life of the data (for example, clicking in to the most of the sections shows the archive of data, like listening, reading, and watching). This is especially important with the sites that don’t have public APIs, as I’m relying on my profiles’ RSS feeds, which only contain the most recent data. Without relying on the data I’ve already fetched and stored, I’ll lose the older data as it rolls off the feed.
Ready, Set, Action!
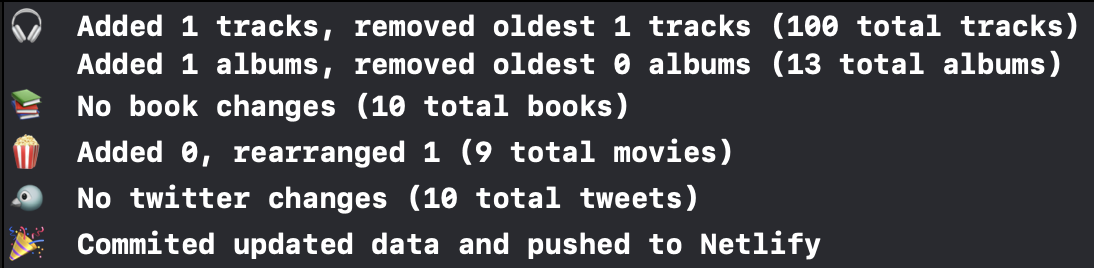
Now whenever I want to update my site, it’s a matter of running my little Swift program, which checks the various feeds, diffs against my local data source, parses and updates as needed, and then pushes the resulting changes (if any) to Netlify for rebuilding and publishing.
I even have it output some cool info as it’s running so I can see what was done on my behalf2.
So that’s about it! If no one cares and never visits, that’s totally fine3. But if you do get wondering: “What is Joe up to?”, I hope this little pet project4 will help answer that. If you have any suggestions for sections I could add, let me know!